4 Webscraping with R
Nowadays, we manage a very huge part of our life online. This has an important side-effect: we can collect enormous data from the web for our researches. You can access data about shops, blogs, social media etc. The target of this chapter is to give a brief introduction how you can collect this data effectively. We will need a new package for this purpose: rvest
We will scrape the data from hasznaltauto, which is the online second hand car market of Hungary. Lets navigate to the page in our browser and lets click on search.
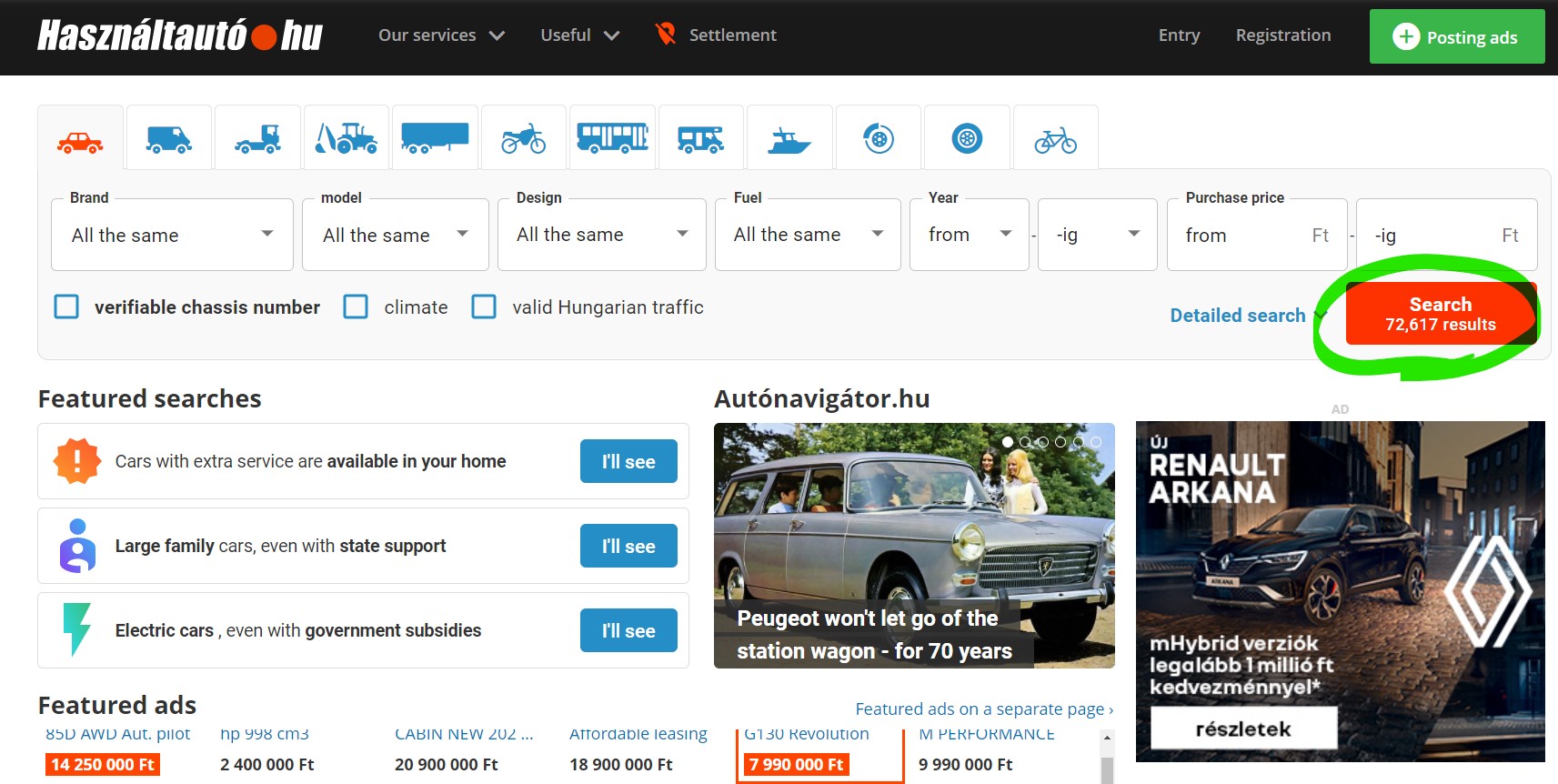
Figure 4.1: www.hasznaltauto.hu/
Now we have to copy and paste the new url from the browser to Rstudio. This will be the first link we want to visit while scraping. Lets assign this url as url in R.
url <- "https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDAD [...]" # long url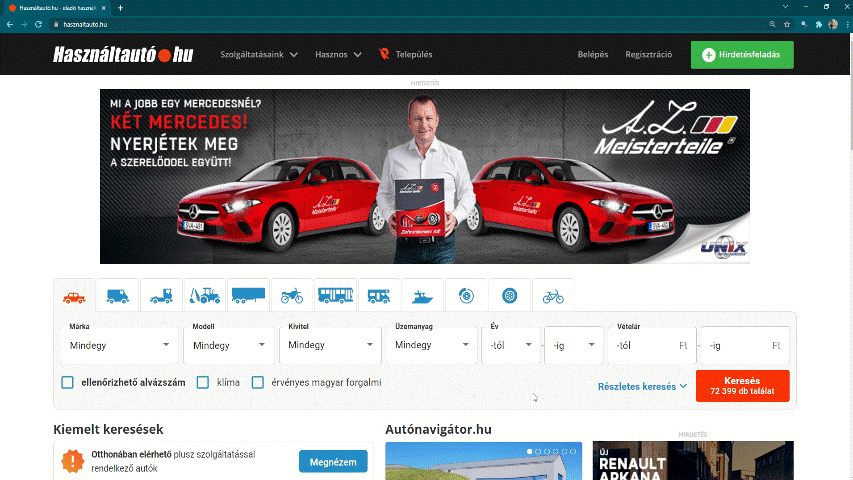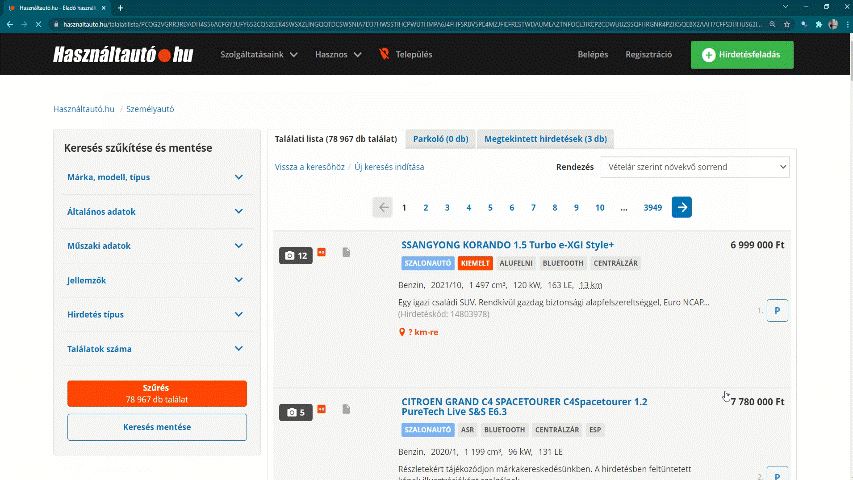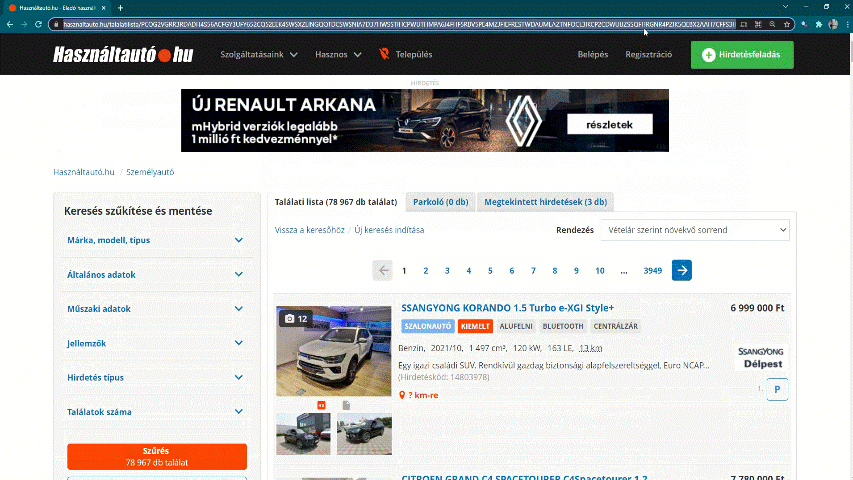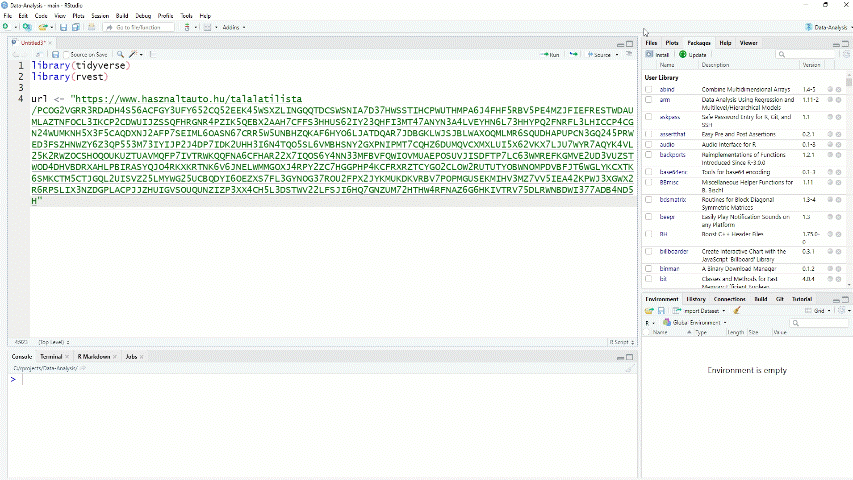
Figure 4.2: Click on the search button.
The next step is load the website into your R session. This can be done by the read_html function from the rvest package.
page <- read_html(url)
page
#> {html_document}
#> <html lang="hu-HU">
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
#> [2] <body>\n <script type="text/javascript">var utag_data = {"website":"ha ...4.1 Naviagtion on the page
Now we can see the webpage as html codes in RStudio. This is the same what you get if you open developer view in your browser.
Figure 4.3: Developer view in browser.
In the developer view, you can find the information that is relevant to you and select it using the html_nodes function. Alternatively, however, there is a simpler method. Add Selector Gadget to your browser. This add-on helps you find the ID of an item by clicking on it. This way, you can navigate without having web development skills. We can easily install this add-on in chrome and edge, just search for its name and the first hit should be this.
Figure 4.4: Add Selector Gadget to your browser.
You can activate the add-on from the menu of your browser.
First, find the IDs for the car ads. To do this, first select the name of a specific car and then mark everything you do not want to include. The target is to make every car ads title to yellow or green, but nothing else should be green.
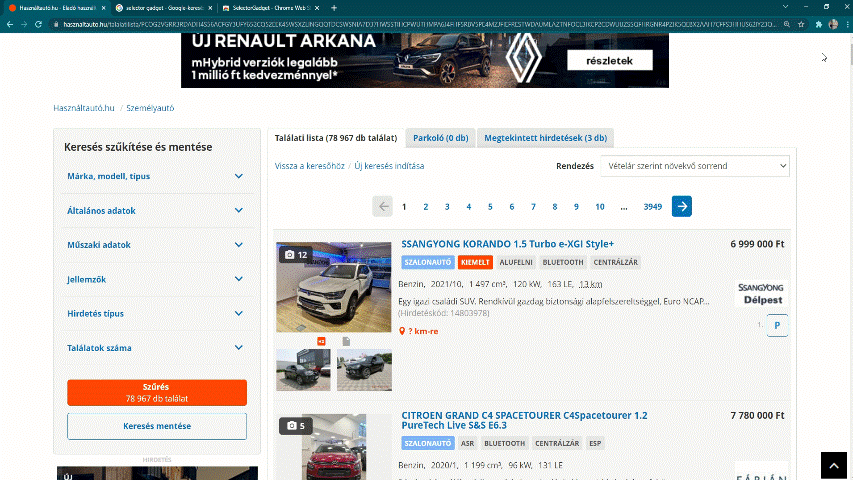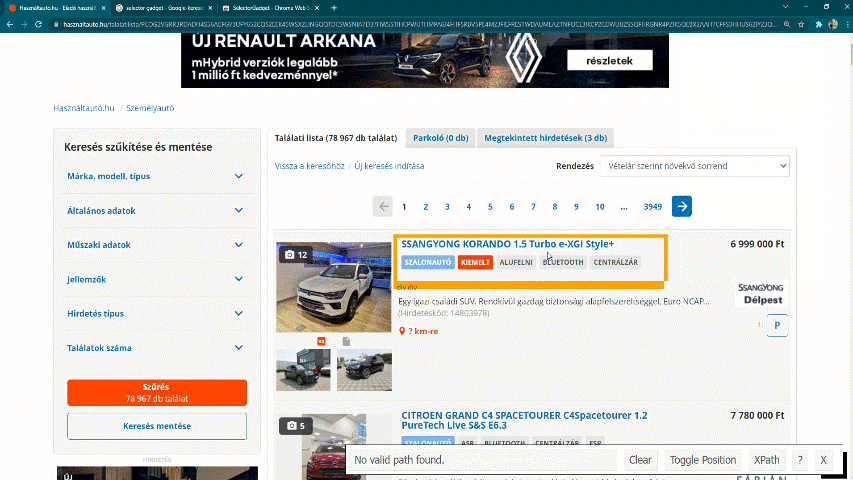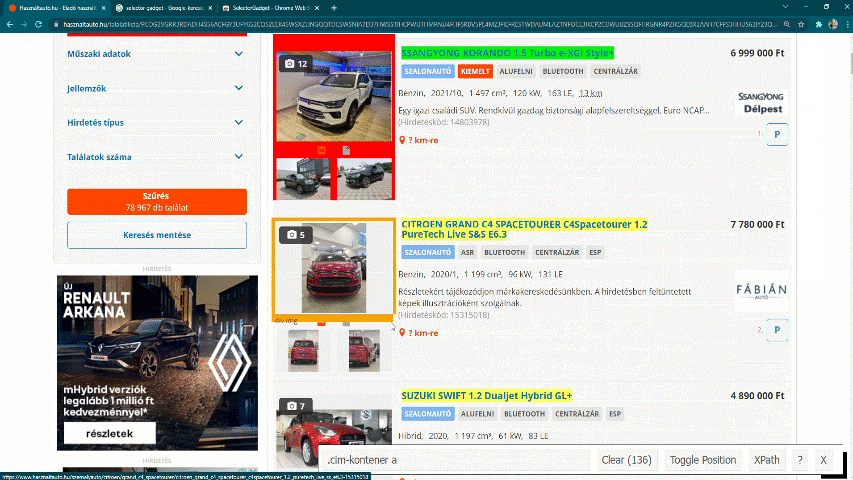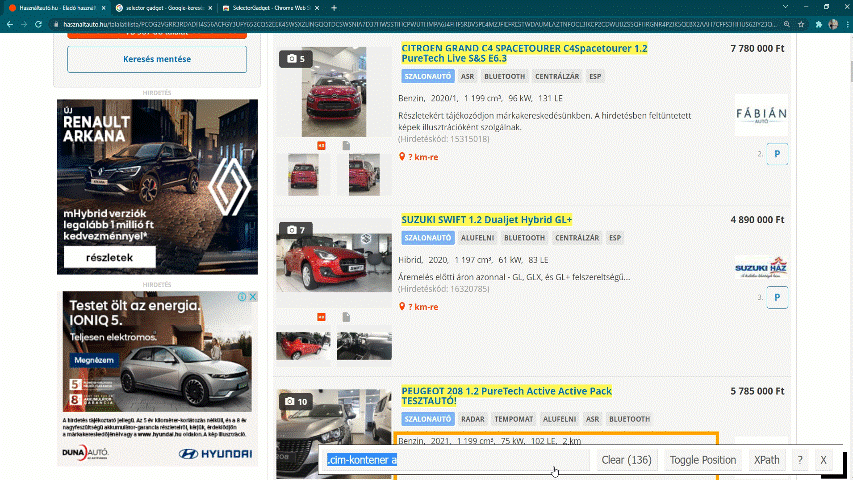
Figure 4.5: Using Selector Gadget to find IDs for the car ads.
If you have the ID you are looking for, put it in the html_nodes function. The code above selects the ad titles from the page.
my_node <- page %>%
html_nodes(".cim-kontener a")
my_node
#> {xml_nodeset (157)}
#> [1] <a class="btn hagomb hagomb-nagy parkoloBtn parkolo-nolabel" data-hirkod ...
#> [2] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/ssangyong/kora ...
#> [3] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/ssangyong/kora ...
#> [4] <a class="btn hagomb hagomb-nagy parkoloBtn parkolo-nolabel" data-hirkod ...
#> [5] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/citroen/grand_ ...
#> [6] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/citroen/grand_ ...
#> [7] <a class="btn hagomb hagomb-nagy parkoloBtn parkolo-nolabel" data-hirkod ...
#> [8] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/suzuki/swift/s ...
#> [9] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/suzuki/swift/s ...
#> [10] <a class="btn hagomb hagomb-nagy parkoloBtn parkolo-nolabel" data-hirkod ...
#> [11] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/peugeot/208/pe ...
#> [12] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/peugeot/208/pe ...
#> [13] <a class="btn hagomb hagomb-nagy parkoloBtn parkolo-nolabel" data-hirkod ...
#> [14] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/opel/combo/ope ...
#> [15] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/opel/combo/ope ...
#> [16] <a class="btn hagomb hagomb-nagy parkoloBtn parkolo-nolabel" data-hirkod ...
#> [17] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/opel/insignia/ ...
#> [18] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/opel/insignia/ ...
#> [19] <a class="btn hagomb hagomb-nagy parkoloBtn parkolo-nolabel" data-hirkod ...
#> [20] <a class="" href="https://www.hasznaltauto.hu/szemelyauto/opel/zafira_li ...
#> ...But this is still an html_code.If we want to keep the text of the element, we use the html_text function, but if we are interested in the url it points to, we use thehtml_attr function. In the latter case, it is always necessary to specify the href element, ie which web page you are referring to.
name_of_the_car <- my_node %>%
html_text()
name_of_the_car
#> [1] "P"
#> [2] "SSANGYONG KORANDO 1.5 Turbo e-XGI Style+"
#> [3] "SSANGYONG KORANDO 1.5 Turbo e-XGI Style+"
#> [4] "P"
#> [5] "CITROEN GRAND C4 SPACETOURER C4Spacetourer 1.2 PureTech Live S&S E6.3"
#> [6] "CITROEN GRAND C4 SPACETOURER C4Spacetourer 1.2 PureTech Live S&S E6.3"
#> [7] "P"
#> [8] "SUZUKI SWIFT 1.2 Dualjet Hybrid GL+"
#> [9] "SUZUKI SWIFT 1.2 Dualjet Hybrid GL+"
#> [10] "P"
#> [11] "PEUGEOT 208 1.2 PureTech Active Active Pack TESZTAUTÓ!"
#> [12] "PEUGEOT 208 1.2 PureTech Active Active Pack TESZTAUTÓ!"
#> [13] "P"
#> [14] "OPEL COMBO Life 1.2 T Enjoy 2.0t XL (7 személyes ) CÉGEKNEK 0.5%-OS ÜGYLETI KAMATTAL!"
#> [15] "OPEL COMBO Life 1.2 T Enjoy 2.0t XL (7 személyes ) CÉGEKNEK 0.5%-OS ÜGYLETI KAMATTAL!"
#> [16] "P"
#> [17] "OPEL INSIGNIA Grand Sport 1.4 T Business Edition tesztautó"
#> [18] "OPEL INSIGNIA Grand Sport 1.4 T Business Edition tesztautó"
#> [19] "P"
#> [20] "OPEL ZAFIRA LIFE 1.5 D Business Edition S (9 személyes ) 5 ÉV GARANCIA. Rendelhető !"
#> [21] "OPEL ZAFIRA LIFE 1.5 D Business Edition S (9 személyes ) 5 ÉV GARANCIA. Rendelhető !"
#> [22] "P"
#> [23] "SUZUKI VITARA 1.4 Hybrid GL+"
#> [24] "SUZUKI VITARA 1.4 Hybrid GL+"
#> [25] "P"
#> [26] "SUZUKI IGNIS 1.2 Hybrid GL+"
#> [27] "SUZUKI IGNIS 1.2 Hybrid GL+"
#> [28] "P"
#> [29] "CITROEN C5 AIRCROSS 1.2 PureTech Feel"
#> [30] "CITROEN C5 AIRCROSS 1.2 PureTech Feel"
#> [31] "P"
#> [32] "OPEL CROSSLAND 1.2 Edition"
#> [33] "OPEL CROSSLAND 1.2 Edition"
#> [34] "P"
#> [35] "FORD MONDEO 2.0 TDCi Business KULTRÁLT ESZTÉTIKUM. MEGBÍZHATÓ MŰSZAKI ÁLLAPOT"
#> [36] "FORD MONDEO 2.0 TDCi Business KULTRÁLT ESZTÉTIKUM. MEGBÍZHATÓ MŰSZAKI ÁLLAPOT"
#> [37] "P"
#> [38] "VOLKSWAGEN GOLF VII 2.0 TDI Highline GYÁRI FÉNYEZÉS. MAGASAN EXTRÁZOTT. SPORT BELSŐVEL ÉS HANGULAT VILÁGÍTÁSSAL!!!"
#> [39] "VOLKSWAGEN GOLF VII 2.0 TDI Highline GYÁRI FÉNYEZÉS. MAGASAN EXTRÁZOTT. SPORT BELSŐVEL ÉS HANGULAT VILÁGÍTÁSSAL!!!"
#> [40] "P"
#> [41] "CITROEN C4 e-C4 50kWh Feel Plus Elektromos autó támogatással: 9.490.000 Ft"
#> [42] "CITROEN C4 e-C4 50kWh Feel Plus Elektromos autó támogatással: 9.490.000 Ft"
#> [43] "P"
#> [44] "SSANGYONG TIVOLI 1.5 GDi-T Style"
#> [45] "SSANGYONG TIVOLI 1.5 GDi-T Style"
#> [46] "P"
#> [47] "BMW I3 120Ah (Automata) ZÖLD RENDSZÁM - Navigáció - Hővédő üvegezés - Hőszivattyú"
#> [48] "BMW I3 120Ah (Automata) ZÖLD RENDSZÁM - Navigáció - Hővédő üvegezés - Hőszivattyú"
#> [49] "P"
#> [50] "OPEL MOKKA 1.2 T Edition CÉGEKNEK 0.5%-OS ÜGYLETI KAMATTAL!"
#> [51] "OPEL MOKKA 1.2 T Edition CÉGEKNEK 0.5%-OS ÜGYLETI KAMATTAL!"
#> [52] "P"
#> [53] "SSANGYONG REXTON 2.2 e-XDI Premium 4WD (Automata) (7 személyes )"
#> [54] "SSANGYONG REXTON 2.2 e-XDI Premium 4WD (Automata) (7 személyes )"
#> [55] "P"
#> [56] "BMW 520d xDrive (Automata) M Sport - Lézervilágítás - Napfénytető - Elektr. memóriás ülések - Service Inclu"
#> [57] "BMW 520d xDrive (Automata) M Sport - Lézervilágítás - Napfénytető - Elektr. memóriás ülések - Service Inclu"
#> [58] "P"
#> [59] "CITROEN C3 1.2 PureTech Live S&S"
#> [60] "CITROEN C3 1.2 PureTech Live S&S"
#> [61] "P"
#> [62] "FORD KUGA 1.5 EcoBoost Titanium Technology ELSŐ TULAJDONOSTÓL. GARANTÁLT KILÓMÉTER. VÉGIG VEZETETT SZERVIZKÖNYV!!!"
#> [63] "FORD KUGA 1.5 EcoBoost Titanium Technology ELSŐ TULAJDONOSTÓL. GARANTÁLT KILÓMÉTER. VÉGIG VEZETETT SZERVIZKÖNYV!!!"
#> [64] "P"
#> [65] "OPEL CORSA F 1.2 Edition CÉGEKNEK 0.5%-OS ÜGYLETI KAMATTAL!"
#> [66] "OPEL CORSA F 1.2 Edition CÉGEKNEK 0.5%-OS ÜGYLETI KAMATTAL!"
#> [67] "P"
#> [68] "NISSAN QASHQAI 1.3 DIG-T Acenta Készletkisöprés a Gablini M3-ban!"
#> [69] "NISSAN QASHQAI 1.3 DIG-T Acenta Készletkisöprés a Gablini M3-ban!"
#> [70] "P"
#> [71] "NISSAN JUKE 1.0 DIG-T Acenta + Comfort csomag. Új Juke készletről!!! Gablini M3"
#> [72] "NISSAN JUKE 1.0 DIG-T Acenta + Comfort csomag. Új Juke készletről!!! Gablini M3"
#> [73] "P"
#> [74] "NISSAN MICRA 1.0 IG-T Acenta"
#> [75] "NISSAN MICRA 1.0 IG-T Acenta"
#> [76] "P"
#> [77] "OPEL ASTRA K 1.2 T Business Edition"
#> [78] "OPEL ASTRA K 1.2 T Business Edition"
#> [79] "P"
#> [80] "NISSAN LEAF Acenta 40kWh (Automata) Készletről azonnal Zuglóban is! Több színben!"
#> [81] "NISSAN LEAF Acenta 40kWh (Automata) Készletről azonnal Zuglóban is! Több színben!"
#> [82] "P"
#> [83] "VOLKSWAGEN PASSAT VIII 2.0 TDI Highline BMT ELSŐ TULAJDONOSTÓL. GYÁRI FÉNYEZÉS. GARANTÁLT KILÓMÉTER!!!"
#> [84] "VOLKSWAGEN PASSAT VIII 2.0 TDI Highline BMT ELSŐ TULAJDONOSTÓL. GYÁRI FÉNYEZÉS. GARANTÁLT KILÓMÉTER!!!"
#> [85] "P"
#> [86] "DACIA DUSTER 1.5 Blue dCi Essential ELSŐ TULAJDONOSTÓL. VALÓS KILÓMÉTERREL. SZALON ÁLLAPOT!!!"
#> [87] "DACIA DUSTER 1.5 Blue dCi Essential ELSŐ TULAJDONOSTÓL. VALÓS KILÓMÉTERREL. SZALON ÁLLAPOT!!!"
#> [88] "P"
#> [89] "OPEL GRANDLAND X 1.2 T Business Edition"
#> [90] "OPEL GRANDLAND X 1.2 T Business Edition"
#> [91] "P"
#> [92] "HYUNDAI TUCSON 1.6 T-GDI Travel DCT Magyarországi! 1. Tulajdonos! Gyári garanciális! Sérülésmentes!"
#> [93] "HYUNDAI TUCSON 1.6 T-GDI Travel DCT Magyarországi! 1. Tulajdonos! Gyári garanciális! Sérülésmentes!"
#> [94] "P"
#> [95] "MAZDA 2 1.5 Attraction Magyarországi!31.000KM!1-tulajdonos!"
#> [96] "MAZDA 2 1.5 Attraction Magyarországi!31.000KM!1-tulajdonos!"
#> [97] "P"
#> [98] "TOYOTA AVENSIS Wagon 1.8 Sol Magyarországi! 1. Tulajdonos! Végig vezetett szervizkönyv!"
#> [99] "TOYOTA AVENSIS Wagon 1.8 Sol Magyarországi! 1. Tulajdonos! Végig vezetett szervizkönyv!"
#> [100] "P"
#> [101] "HONDA CR-V 2.2 i-DTEC Lifestyle Magyarországi!Kitűnő állapot!Már az új 4. generációs CR-V!"
#> [102] "HONDA CR-V 2.2 i-DTEC Lifestyle Magyarországi!Kitűnő állapot!Már az új 4. generációs CR-V!"
#> [103] "P"
#> [104] "FORD FIESTA 1.4 Colourline Magyarországi!99000Km!Szervizkönyv!"
#> [105] "FORD FIESTA 1.4 Colourline Magyarországi!99000Km!Szervizkönyv!"
#> [106] "P"
#> [107] "OPEL VIVARO 2.0 D Combi L 2022-ben érkezik megérkezik"
#> [108] "OPEL VIVARO 2.0 D Combi L 2022-ben érkezik megérkezik"
#> [109] "P"
#> [110] "CITROEN C3 AIRCROSS 1.2 PureTech Feel S&S"
#> [111] "CITROEN C3 AIRCROSS 1.2 PureTech Feel S&S"
#> [112] "P"
#> [113] "SKODA OCTAVIA 1.8 TSI Style DSG Magyarországi! Sérülésmentes! Vezetett szervizkönyv!"
#> [114] "SKODA OCTAVIA 1.8 TSI Style DSG Magyarországi! Sérülésmentes! Vezetett szervizkönyv!"
#> [115] "P"
#> [116] "FIAT 500 1.2 8V Lounge Magyarországi!33.500KM!Újszerű!"
#> [117] "FIAT 500 1.2 8V Lounge Magyarországi!33.500KM!Újszerű!"
#> [118] "P"
#> [119] "MERCEDES-BENZ C 180 9G-TRONIC Magyaro.-i Garanciális!"
#> [120] "P"
#> [121] "VOLVO XC40 2.0 [T4] R-Design AWD Geartronic Magyaro.-i első üzembeh"
#> [122] "P"
#> [123] "MERCEDES-BENZ GLS 500 4Matic Aut. (7 sz.) Magyaro.-i Garanciális! ISP!"
#> [124] "P"
#> [125] "MERCEDES-BENZ GLC-OSZTÁLY GLC 400 d 4Matic 9G-TRONIC Nettó ár:18 889 763Ft"
#> [126] "P"
#> [127] "MERCEDES-BENZ A 180 (BlueEFFICIENCY) Urban Akár +1 Év Garancia!"
#> [128] "P"
#> [129] "VOLVO XC60 2.4 D Kinetic Geartronic AWD Magyarországi. végig vezetett szervizkönyv!"
#> [130] "P"
#> [131] "OPEL CROSSLAND X 1.2 Start-Stop Enjoy Nyitva vagyunk!"
#> [132] "P"
#> [133] "OPEL CROSSLAND X 1.2 Start-Stop Enjoy CÉGEKNEK AKÁR 0.5 % -os FIX Ügyleti FINANSZÍROZÁS!"
#> [134] "P"
#> [135] "OPEL ASTRA K 1.2 T BEST Készletsöprő akció az Opel Wallis-nál! Nyitva vagyunk!"
#> [136] "P"
#> [137] "OPEL ASTRA K 1.2 T BEST Készletsöprő akció az Opel Wallis-nál! Nyitva vagyunk!"
#> [138] "P"
#> [139] "OPEL CROSSLAND X 1.2 Start-Stop Enjoy CÉGEKNEK AKÁR 0.5 % -os FIX Ügyleti FINANSZÍROZÁS!"
#> [140] "P"
#> [141] "OPEL ASTRA K Sports Tourer 1.2 T GS Line MAGYARORSZÁGI GYÁRI GARANCIA MAGAS FELSZERELTSÉG"
#> [142] "P"
#> [143] "OPEL ASTRA K 1.2 T Business Edition Opel Wallistól"
#> [144] "P"
#> [145] "OPEL CROSSLAND 1.2 Edition // Demo Autó //"
#> [146] "P"
#> [147] "OPEL ASTRA K Sports Tourer 1.2 T GS Line GYÁRI GARANCIA MAGYARORSZÁGI ÜZEMBEHELYEZÉS"
#> [148] "P"
#> [149] "OPEL CROSSLAND 1.2 Business Edition Megbízható társ kevés km-rel"
#> [150] "P"
#> [151] "OPEL ASTRA K Sports Tourer 1.2 T Edition MAGYARORSZÁGI ÜZEMBE HELYEZÉS GYÁRI GARANCIA"
#> [152] "P"
#> [153] "OPEL CROSSLAND X 1.2 T Start-Stop Enjoy CÉGEKNEK AKÁR 0.5 % -os FIX Ügyleti FINANSZÍROZÁS!"
#> [154] "P"
#> [155] "MERCEDES-BENZ B 180 Style MO-I.NAVIGÁCIÓ.66500km"
#> [156] "P"
#> [157] "BMW 218d (Automata)"4.2 Find the link
url_to_car <- my_node %>%
html_attr("href")
url_to_car
#> [1] NA
#> [2] "https://www.hasznaltauto.hu/szemelyauto/ssangyong/korando/ssangyong_korando_1.5_turbo_e-xgi_style_plusz-14803978"
#> [3] "https://www.hasznaltauto.hu/szemelyauto/ssangyong/korando/ssangyong_korando_1.5_turbo_e-xgi_style_plusz-14803978"
#> [4] NA
#> [5] "https://www.hasznaltauto.hu/szemelyauto/citroen/grand_c4_spacetourer/citroen_grand_c4_spacetourer_c4spacetourer_1.2_puretech_live_ss_e6.3-15315018"
#> [6] "https://www.hasznaltauto.hu/szemelyauto/citroen/grand_c4_spacetourer/citroen_grand_c4_spacetourer_c4spacetourer_1.2_puretech_live_ss_e6.3-15315018"
#> [7] NA
#> [8] "https://www.hasznaltauto.hu/szemelyauto/suzuki/swift/suzuki_swift_1.2_dualjet_hybrid_gl_plusz-16320785"
#> [9] "https://www.hasznaltauto.hu/szemelyauto/suzuki/swift/suzuki_swift_1.2_dualjet_hybrid_gl_plusz-16320785"
#> [10] NA
#> [11] "https://www.hasznaltauto.hu/szemelyauto/peugeot/208/peugeot_208_1.2_puretech_active_active_pack_tesztauto-16706957"
#> [12] "https://www.hasznaltauto.hu/szemelyauto/peugeot/208/peugeot_208_1.2_puretech_active_active_pack_tesztauto-16706957"
#> [13] NA
#> [14] "https://www.hasznaltauto.hu/szemelyauto/opel/combo/opel_combo_life_1.2_t_enjoy_2.0t_xl_7_szemelyes_cegeknek_0.5-os_ugyleti_kamattal-16776038"
#> [15] "https://www.hasznaltauto.hu/szemelyauto/opel/combo/opel_combo_life_1.2_t_enjoy_2.0t_xl_7_szemelyes_cegeknek_0.5-os_ugyleti_kamattal-16776038"
#> [16] NA
#> [17] "https://www.hasznaltauto.hu/szemelyauto/opel/insignia/opel_insignia_grand_sport_1.4_t_business_edition_tesztauto-16791117"
#> [18] "https://www.hasznaltauto.hu/szemelyauto/opel/insignia/opel_insignia_grand_sport_1.4_t_business_edition_tesztauto-16791117"
#> [19] NA
#> [20] "https://www.hasznaltauto.hu/szemelyauto/opel/zafira_life/opel_zafira_life_1.5_d_business_edition_s_9_szemelyes_5_ev_garancia_rendelheto-16812389"
#> [21] "https://www.hasznaltauto.hu/szemelyauto/opel/zafira_life/opel_zafira_life_1.5_d_business_edition_s_9_szemelyes_5_ev_garancia_rendelheto-16812389"
#> [22] NA
#> [23] "https://www.hasznaltauto.hu/szemelyauto/suzuki/vitara/suzuki_vitara_1.4_hybrid_gl_plusz-16844171"
#> [24] "https://www.hasznaltauto.hu/szemelyauto/suzuki/vitara/suzuki_vitara_1.4_hybrid_gl_plusz-16844171"
#> [25] NA
#> [26] "https://www.hasznaltauto.hu/szemelyauto/suzuki/ignis/suzuki_ignis_1.2_hybrid_gl_plusz-16847562"
#> [27] "https://www.hasznaltauto.hu/szemelyauto/suzuki/ignis/suzuki_ignis_1.2_hybrid_gl_plusz-16847562"
#> [28] NA
#> [29] "https://www.hasznaltauto.hu/szemelyauto/citroen/c5_aircross/citroen_c5_aircross_1.2_puretech_feel-16930069"
#> [30] "https://www.hasznaltauto.hu/szemelyauto/citroen/c5_aircross/citroen_c5_aircross_1.2_puretech_feel-16930069"
#> [31] NA
#> [32] "https://www.hasznaltauto.hu/szemelyauto/opel/crossland/opel_crossland_1.2_edition-17018658"
#> [33] "https://www.hasznaltauto.hu/szemelyauto/opel/crossland/opel_crossland_1.2_edition-17018658"
#> [34] NA
#> [35] "https://www.hasznaltauto.hu/szemelyauto/ford/mondeo/ford_mondeo_2.0_tdci_business_kultralt_esztetikum_megbizhato_muszaki_allapot-17040232"
#> [36] "https://www.hasznaltauto.hu/szemelyauto/ford/mondeo/ford_mondeo_2.0_tdci_business_kultralt_esztetikum_megbizhato_muszaki_allapot-17040232"
#> [37] NA
#> [38] "https://www.hasznaltauto.hu/szemelyauto/volkswagen/golf_vii/volkswagen_golf_vii_2.0_tdi_highline_gyari_fenyezes_magasan_extrazott_sport_belsovel_es_hangulat_vilagitassal-17055891"
#> [39] "https://www.hasznaltauto.hu/szemelyauto/volkswagen/golf_vii/volkswagen_golf_vii_2.0_tdi_highline_gyari_fenyezes_magasan_extrazott_sport_belsovel_es_hangulat_vilagitassal-17055891"
#> [40] NA
#> [41] "https://www.hasznaltauto.hu/szemelyauto/citroen/c4/citroen_c4_e-c4_50kwh_feel_plus_elektromos_auto_tamogatassal_9.490.000_ft-17066667"
#> [42] "https://www.hasznaltauto.hu/szemelyauto/citroen/c4/citroen_c4_e-c4_50kwh_feel_plus_elektromos_auto_tamogatassal_9.490.000_ft-17066667"
#> [43] NA
#> [44] "https://www.hasznaltauto.hu/szemelyauto/ssangyong/tivoli/ssangyong_tivoli_1.5_gdi-t_style-17067259"
#> [45] "https://www.hasznaltauto.hu/szemelyauto/ssangyong/tivoli/ssangyong_tivoli_1.5_gdi-t_style-17067259"
#> [46] NA
#> [47] "https://www.hasznaltauto.hu/szemelyauto/bmw/i3/bmw_i3_120ah_automata_zold_rendszam_-_navigacio_-_hovedo_uvegezes_-_hoszivattyu-17068472"
#> [48] "https://www.hasznaltauto.hu/szemelyauto/bmw/i3/bmw_i3_120ah_automata_zold_rendszam_-_navigacio_-_hovedo_uvegezes_-_hoszivattyu-17068472"
#> [49] NA
#> [50] "https://www.hasznaltauto.hu/szemelyauto/opel/mokka/opel_mokka_1.2_t_edition_cegeknek_0.5-os_ugyleti_kamattal-17092798"
#> [51] "https://www.hasznaltauto.hu/szemelyauto/opel/mokka/opel_mokka_1.2_t_edition_cegeknek_0.5-os_ugyleti_kamattal-17092798"
#> [52] NA
#> [53] "https://www.hasznaltauto.hu/szemelyauto/ssangyong/rexton/ssangyong_rexton_2.2_e-xdi_premium_4wd_automata_7_szemelyes-17113913"
#> [54] "https://www.hasznaltauto.hu/szemelyauto/ssangyong/rexton/ssangyong_rexton_2.2_e-xdi_premium_4wd_automata_7_szemelyes-17113913"
#> [55] NA
#> [56] "https://www.hasznaltauto.hu/szemelyauto/bmw/520/bmw_520d_xdrive_automata_m_sport_-_lezervilagitas_-_napfenyteto_-_elektr_memorias_ulesek_-_service_inclu-17122247"
#> [57] "https://www.hasznaltauto.hu/szemelyauto/bmw/520/bmw_520d_xdrive_automata_m_sport_-_lezervilagitas_-_napfenyteto_-_elektr_memorias_ulesek_-_service_inclu-17122247"
#> [58] NA
#> [59] "https://www.hasznaltauto.hu/szemelyauto/citroen/c3/citroen_c3_1.2_puretech_live_ss-17183148"
#> [60] "https://www.hasznaltauto.hu/szemelyauto/citroen/c3/citroen_c3_1.2_puretech_live_ss-17183148"
#> [61] NA
#> [62] "https://www.hasznaltauto.hu/szemelyauto/ford/kuga/ford_kuga_1.5_ecoboost_titanium_technology_elso_tulajdonostol_garantalt_kilometer_vegig_vezetett_szervizkonyv-17356145"
#> [63] "https://www.hasznaltauto.hu/szemelyauto/ford/kuga/ford_kuga_1.5_ecoboost_titanium_technology_elso_tulajdonostol_garantalt_kilometer_vegig_vezetett_szervizkonyv-17356145"
#> [64] NA
#> [65] "https://www.hasznaltauto.hu/szemelyauto/opel/corsa_f/opel_corsa_f_1.2_edition_cegeknek_0.5-os_ugyleti_kamattal-17415708"
#> [66] "https://www.hasznaltauto.hu/szemelyauto/opel/corsa_f/opel_corsa_f_1.2_edition_cegeknek_0.5-os_ugyleti_kamattal-17415708"
#> [67] NA
#> [68] "https://www.hasznaltauto.hu/szemelyauto/nissan/qashqai/nissan_qashqai_1.3_dig-t_acenta_keszletkisopres_a_gablini_m3-ban-17435860"
#> [69] "https://www.hasznaltauto.hu/szemelyauto/nissan/qashqai/nissan_qashqai_1.3_dig-t_acenta_keszletkisopres_a_gablini_m3-ban-17435860"
#> [70] NA
#> [71] "https://www.hasznaltauto.hu/szemelyauto/nissan/juke/nissan_juke_1.0_dig-t_acenta_plusz_comfort_csomag_uj_juke_keszletrol_gablini_m3-17436209"
#> [72] "https://www.hasznaltauto.hu/szemelyauto/nissan/juke/nissan_juke_1.0_dig-t_acenta_plusz_comfort_csomag_uj_juke_keszletrol_gablini_m3-17436209"
#> [73] NA
#> [74] "https://www.hasznaltauto.hu/szemelyauto/nissan/micra/nissan_micra_1.0_ig-t_acenta-17436352"
#> [75] "https://www.hasznaltauto.hu/szemelyauto/nissan/micra/nissan_micra_1.0_ig-t_acenta-17436352"
#> [76] NA
#> [77] "https://www.hasznaltauto.hu/szemelyauto/opel/astra_k/opel_astra_k_1.2_t_business_edition-17443440"
#> [78] "https://www.hasznaltauto.hu/szemelyauto/opel/astra_k/opel_astra_k_1.2_t_business_edition-17443440"
#> [79] NA
#> [80] "https://www.hasznaltauto.hu/szemelyauto/nissan/leaf/nissan_leaf_acenta_40kwh_automata_keszletrol_azonnal_zugloban_is_tobb_szinben-17444263"
#> [81] "https://www.hasznaltauto.hu/szemelyauto/nissan/leaf/nissan_leaf_acenta_40kwh_automata_keszletrol_azonnal_zugloban_is_tobb_szinben-17444263"
#> [82] NA
#> [83] "https://www.hasznaltauto.hu/szemelyauto/volkswagen/passat_viii/volkswagen_passat_viii_2.0_tdi_highline_bmt_elso_tulajdonostol_gyari_fenyezes_garantalt_kilometer-17447909"
#> [84] "https://www.hasznaltauto.hu/szemelyauto/volkswagen/passat_viii/volkswagen_passat_viii_2.0_tdi_highline_bmt_elso_tulajdonostol_gyari_fenyezes_garantalt_kilometer-17447909"
#> [85] NA
#> [86] "https://www.hasznaltauto.hu/szemelyauto/dacia/duster/dacia_duster_1.5_blue_dci_essential_elso_tulajdonostol_valos_kilometerrel_szalon_allapot-17512287"
#> [87] "https://www.hasznaltauto.hu/szemelyauto/dacia/duster/dacia_duster_1.5_blue_dci_essential_elso_tulajdonostol_valos_kilometerrel_szalon_allapot-17512287"
#> [88] NA
#> [89] "https://www.hasznaltauto.hu/szemelyauto/opel/grandland_x/opel_grandland_x_1.2_t_business_edition-17539934"
#> [90] "https://www.hasznaltauto.hu/szemelyauto/opel/grandland_x/opel_grandland_x_1.2_t_business_edition-17539934"
#> [91] NA
#> [92] "https://www.hasznaltauto.hu/szemelyauto/hyundai/tucson/hyundai_tucson_1.6_t-gdi_travel_dct_magyarorszagi_1_tulajdonos_gyari_garancialis_serulesmentes-17564234"
#> [93] "https://www.hasznaltauto.hu/szemelyauto/hyundai/tucson/hyundai_tucson_1.6_t-gdi_travel_dct_magyarorszagi_1_tulajdonos_gyari_garancialis_serulesmentes-17564234"
#> [94] NA
#> [95] "https://www.hasznaltauto.hu/szemelyauto/mazda/2/mazda_2_1.5_attraction_magyarorszagi31.000km1-tulajdonos-17582320"
#> [96] "https://www.hasznaltauto.hu/szemelyauto/mazda/2/mazda_2_1.5_attraction_magyarorszagi31.000km1-tulajdonos-17582320"
#> [97] NA
#> [98] "https://www.hasznaltauto.hu/szemelyauto/toyota/avensis/toyota_avensis_wagon_1.8_sol_magyarorszagi_1_tulajdonos_vegig_vezetett_szervizkonyv-17582338"
#> [99] "https://www.hasznaltauto.hu/szemelyauto/toyota/avensis/toyota_avensis_wagon_1.8_sol_magyarorszagi_1_tulajdonos_vegig_vezetett_szervizkonyv-17582338"
#> [100] NA
#> [101] "https://www.hasznaltauto.hu/szemelyauto/honda/cr-v/honda_cr-v_2.2_i-dtec_lifestyle_magyarorszagikituno_allapotmar_az_uj_4_generacios_cr-v-17582368"
#> [102] "https://www.hasznaltauto.hu/szemelyauto/honda/cr-v/honda_cr-v_2.2_i-dtec_lifestyle_magyarorszagikituno_allapotmar_az_uj_4_generacios_cr-v-17582368"
#> [103] NA
#> [104] "https://www.hasznaltauto.hu/szemelyauto/ford/fiesta/ford_fiesta_1.4_colourline_magyarorszagi99000kmszervizkonyv-17583871"
#> [105] "https://www.hasznaltauto.hu/szemelyauto/ford/fiesta/ford_fiesta_1.4_colourline_magyarorszagi99000kmszervizkonyv-17583871"
#> [106] NA
#> [107] "https://www.hasznaltauto.hu/szemelyauto/opel/vivaro/opel_vivaro_2.0_d_combi_l_2022-ben_erkezik_megerkezik-17588957"
#> [108] "https://www.hasznaltauto.hu/szemelyauto/opel/vivaro/opel_vivaro_2.0_d_combi_l_2022-ben_erkezik_megerkezik-17588957"
#> [109] NA
#> [110] "https://www.hasznaltauto.hu/szemelyauto/citroen/c3_aircross/citroen_c3_aircross_1.2_puretech_feel_ss-17589004"
#> [111] "https://www.hasznaltauto.hu/szemelyauto/citroen/c3_aircross/citroen_c3_aircross_1.2_puretech_feel_ss-17589004"
#> [112] NA
#> [113] "https://www.hasznaltauto.hu/szemelyauto/skoda/octavia/skoda_octavia_1.8_tsi_style_dsg_magyarorszagi_serulesmentes_vezetett_szervizkonyv-17590025"
#> [114] "https://www.hasznaltauto.hu/szemelyauto/skoda/octavia/skoda_octavia_1.8_tsi_style_dsg_magyarorszagi_serulesmentes_vezetett_szervizkonyv-17590025"
#> [115] NA
#> [116] "https://www.hasznaltauto.hu/szemelyauto/fiat/500/fiat_500_1.2_8v_lounge_magyarorszagi33.500kmujszeru-17603291"
#> [117] "https://www.hasznaltauto.hu/szemelyauto/fiat/500/fiat_500_1.2_8v_lounge_magyarorszagi33.500kmujszeru-17603291"
#> [118] NA
#> [119] "https://www.hasznaltauto.hu/szemelyauto/mercedes-benz/c_180/mercedes-benz_c_180_9g-tronic_magyaro-i_garancialis-16447280"
#> [120] NA
#> [121] "https://www.hasznaltauto.hu/szemelyauto/volvo/xc40/volvo_xc40_2.0_t4_r-design_awd_geartronic_magyaro-i_elso_uzembeh-17585530"
#> [122] NA
#> [123] "https://www.hasznaltauto.hu/szemelyauto/mercedes-benz/gls_500/mercedes-benz_gls_500_4matic_aut_7_sz_magyaro-i_garancialis_isp-17594722"
#> [124] NA
#> [125] "https://www.hasznaltauto.hu/szemelyauto/mercedes-benz/glc-osztaly/mercedes-benz_glc-osztaly_glc_400_d_4matic_9g-tronic_netto_ar18_889_763ft-17605413"
#> [126] NA
#> [127] "https://www.hasznaltauto.hu/szemelyauto/mercedes-benz/a_180/mercedes-benz_a_180_blueefficiency_urban_akar_plusz_1_ev_garancia-17143636"
#> [128] NA
#> [129] "https://www.hasznaltauto.hu/szemelyauto/volvo/xc60/volvo_xc60_2.4_d_kinetic_geartronic_awd_magyarorszagi_vegig_vezetett_szervizkonyv-17556556"
#> [130] NA
#> [131] "https://www.hasznaltauto.hu/szemelyauto/opel/crossland_x/opel_crossland_x_1.2_start-stop_enjoy_nyitva_vagyunk-16876962"
#> [132] NA
#> [133] "https://www.hasznaltauto.hu/szemelyauto/opel/crossland_x/opel_crossland_x_1.2_start-stop_enjoy_cegeknek_akar_0.5_-os_fix_ugyleti_finanszirozas-17590806"
#> [134] NA
#> [135] "https://www.hasznaltauto.hu/szemelyauto/opel/astra_k/opel_astra_k_1.2_t_best_keszletsopro_akcio_az_opel_wallis-nal_nyitva_vagyunk-16852314"
#> [136] NA
#> [137] "https://www.hasznaltauto.hu/szemelyauto/opel/astra_k/opel_astra_k_1.2_t_best_keszletsopro_akcio_az_opel_wallis-nal_nyitva_vagyunk-16592509"
#> [138] NA
#> [139] "https://www.hasznaltauto.hu/szemelyauto/opel/crossland_x/opel_crossland_x_1.2_start-stop_enjoy_cegeknek_akar_0.5_-os_fix_ugyleti_finanszirozas-17590650"
#> [140] NA
#> [141] "https://www.hasznaltauto.hu/szemelyauto/opel/astra_k/opel_astra_k_sports_tourer_1.2_t_gs_line_magyarorszagi_gyari_garancia_magas_felszereltseg-17589461"
#> [142] NA
#> [143] "https://www.hasznaltauto.hu/szemelyauto/opel/astra_k/opel_astra_k_1.2_t_business_edition_opel_wallistol-17385241"
#> [144] NA
#> [145] "https://www.hasznaltauto.hu/szemelyauto/opel/crossland/opel_crossland_1.2_edition_demo_auto-17605071"
#> [146] NA
#> [147] "https://www.hasznaltauto.hu/szemelyauto/opel/astra_k/opel_astra_k_sports_tourer_1.2_t_gs_line_gyari_garancia_magyarorszagi_uzembehelyezes-17589255"
#> [148] NA
#> [149] "https://www.hasznaltauto.hu/szemelyauto/opel/crossland/opel_crossland_1.2_business_edition_megbizhato_tars_keves_km-rel-17604760"
#> [150] NA
#> [151] "https://www.hasznaltauto.hu/szemelyauto/opel/astra_k/opel_astra_k_sports_tourer_1.2_t_edition_magyarorszagi_uzembe_helyezes_gyari_garancia-17589607"
#> [152] NA
#> [153] "https://www.hasznaltauto.hu/szemelyauto/opel/crossland_x/opel_crossland_x_1.2_t_start-stop_enjoy_cegeknek_akar_0.5_-os_fix_ugyleti_finanszirozas-17591758"
#> [154] NA
#> [155] "https://www.hasznaltauto.hu/szemelyauto/mercedes-benz/b_180/mercedes-benz_b_180_style_mo-inavigacio66500km-17375831"
#> [156] NA
#> [157] "https://www.hasznaltauto.hu/szemelyauto/bmw/218/bmw_218d_automata-17582426"We’ve now collected the names of all the ads and the url leading to them from the first page. The next step is to collect this data from all pages. However, downloading info from all sites is a lengthy process. Always try the first few pages first and only download them all if you are sure that your program is running without error.
But how do we download data from multiple pages at once? Let’s see if the url changes when we go to the next page.
If we look at the second page of the results list in the browser, we can see that the link has been expanded with a “/page2” member compared to our previous url address. Continue with “/ page3” on page 3, etc.
This way we can easily generate a vector that contains the links to the first 1, 10, 100, 1000 or even all pages. Lets put these into a data.frame.
url_ending <- str_c("/page", 2:10)
url_ending
#> [1] "/page2" "/page3" "/page4" "/page5" "/page6" "/page7" "/page8"
#> [8] "/page9" "/page10"
url_ending <- c("", url_ending) # nothing to add at the first page
url_ending
#> [1] "" "/page2" "/page3" "/page4" "/page5" "/page6" "/page7"
#> [8] "/page8" "/page9" "/page10"
cars_add_df <- tibble(url = str_c(url, url_ending))
cars_add_df
#> # A tibble: 10 x 1
#> url
#> <chr>
#> 1 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~
#> 2 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~
#> 3 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~
#> 4 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~
#> 5 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~
#> 6 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~
#> 7 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~
#> 8 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~
#> 9 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~
#> 10 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY3UFY652CQ5~Taking advantage of the {purr} package, we can load and manipulate entire pages in data frames in a transparent and human-readable (tidy) way.
This will require the map function, but we haven’t talked about using it so far.
Map is very similar to the functions of the apply family. It performs a specific function on each element of a list / vector, but the result always comes in the form of a list.
map(1:5, ~ .^2) # calculate the square of each element (lambda type function)
#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 4
#>
#> [[3]]
#> [1] 9
#>
#> [[4]]
#> [1] 16
#>
#> [[5]]
#> [1] 25
map(1:3, rnorm, 10) # generate rnrom distribution with 1,2,3 element
#> [[1]]
#> [1] 10.53788
#>
#> [[2]]
#> [1] 9.400479 9.796269
#>
#> [[3]]
#> [1] 10.475820 9.653438 10.261546The second example shows that if we specify only one function as the second input, without “~” and “.”, the first input of map will automatically be the first possible input for the specified function, and then the elements added after the function will follow in order. In the present case, we prepared random samples with 1, 2, and 3 elements, where the expected value of the samples is 10, because the first input of the function rnorm is the number of elements (n) and the second is the expected value (mean).
We will now use the map function inside themutate function, so a list will actually be a column of the original table. The elements of this list will be the web pages that are loaded with the read_html function.
cars_add_df %>%
mutate(
page = map(url, read_html)
)
#> # A tibble: 10 x 2
#> url page
#> <chr> <list>
#> 1 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~
#> 2 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~
#> 3 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~
#> 4 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~
#> 5 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~
#> 6 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~
#> 7 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~
#> 8 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~
#> 9 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~
#> 10 https://www.hasznaltauto.hu/talalatilista/PCOG2VGRR3RDADH4S56ACFGY~ <xml_dcm~Now let’s insert a nodes column that contains only the required points of the page, and aurl_to_cars column, which is the links extracted from it. Since this is already a computationally intensive step, it is worth saving the result. Save it with the same name so your environment won’t be full of unnecessary variables.
cars_add_df <- cars_add_df %>%
mutate(
page = map(url, read_html),
nodes = map(page, ~ html_nodes(., ".cim-kontener a")),
ad_title = map(nodes, html_text),
url_to_cars = map(nodes, html_attr, "href")
)
cars_add_df
#> # A tibble: 10 x 5
#> url page nodes ad_title url_to_cars
#> <chr> <list> <list> <list> <list>
#> 1 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [15~ <chr [157]>
#> 2 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [40~ <chr [40]>
#> 3 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [40~ <chr [40]>
#> 4 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [40~ <chr [40]>
#> 5 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [40~ <chr [40]>
#> 6 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [40~ <chr [40]>
#> 7 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [40~ <chr [40]>
#> 8 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [40~ <chr [40]>
#> 9 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [40~ <chr [40]>
#> 10 https://www.hasznaltauto.hu/talalatili~ <xml_d~ <xml_n~ <chr [40~ <chr [40]>From now on, all we need is a column with links and titles, but these are nested. The first cell of the url_to_cars column contains more than a hundred links. This nesting option opens a lot of new doors in the process of data manipulation. Use the unnest function to extract these columns.
cars_add_df %>%
select(url_to_cars, ad_title) %>%
unnest()
#> # A tibble: 517 x 2
#> url_to_cars ad_title
#> <chr> <chr>
#> 1 <NA> P
#> 2 https://www.hasznaltauto.hu/szemelyauto/~ SSANGYONG KORANDO 1.5 Turbo e-XGI ~
#> 3 https://www.hasznaltauto.hu/szemelyauto/~ SSANGYONG KORANDO 1.5 Turbo e-XGI ~
#> 4 <NA> P
#> 5 https://www.hasznaltauto.hu/szemelyauto/~ CITROEN GRAND C4 SPACETOURER C4Spa~
#> 6 https://www.hasznaltauto.hu/szemelyauto/~ CITROEN GRAND C4 SPACETOURER C4Spa~
#> 7 <NA> P
#> 8 https://www.hasznaltauto.hu/szemelyauto/~ SUZUKI SWIFT 1.2 Dualjet Hybrid GL+
#> 9 https://www.hasznaltauto.hu/szemelyauto/~ SUZUKI SWIFT 1.2 Dualjet Hybrid GL+
#> 10 <NA> P
#> # ... with 507 more rowsWe can see that the nodes selection was not entirely perfect (usually not), as there were no matching elements or duplications left.
But now we can still remove the items that don’t fit here. Fortunately, there is no link behind these, and if all columns are the same, unique4 will be our service.
cars_add_df <- cars_add_df %>%
select(url_to_cars, ad_title) %>%
unnest() %>%
na.omit() %>% # remove rows where url_to_cars is missing (NA)
unique() # delete duplications
cars_add_df
#> # A tibble: 239 x 2
#> url_to_cars ad_title
#> <chr> <chr>
#> 1 https://www.hasznaltauto.hu/szemelyaut~ SSANGYONG KORANDO 1.5 Turbo e-XGI St~
#> 2 https://www.hasznaltauto.hu/szemelyaut~ CITROEN GRAND C4 SPACETOURER C4Space~
#> 3 https://www.hasznaltauto.hu/szemelyaut~ SUZUKI SWIFT 1.2 Dualjet Hybrid GL+
#> 4 https://www.hasznaltauto.hu/szemelyaut~ PEUGEOT 208 1.2 PureTech Active Acti~
#> 5 https://www.hasznaltauto.hu/szemelyaut~ OPEL COMBO Life 1.2 T Enjoy 2.0t XL ~
#> 6 https://www.hasznaltauto.hu/szemelyaut~ OPEL INSIGNIA Grand Sport 1.4 T Busi~
#> 7 https://www.hasznaltauto.hu/szemelyaut~ OPEL ZAFIRA LIFE 1.5 D Business Edit~
#> 8 https://www.hasznaltauto.hu/szemelyaut~ SUZUKI VITARA 1.4 Hybrid GL+
#> 9 https://www.hasznaltauto.hu/szemelyaut~ SUZUKI IGNIS 1.2 Hybrid GL+
#> 10 https://www.hasznaltauto.hu/szemelyaut~ CITROEN C5 AIRCROSS 1.2 PureTech Feel
#> # ... with 229 more rowsWe now have a ready-made list of available cars and their links. Let’s visit one in the browser to see what’s next.
4.3 Data from tables
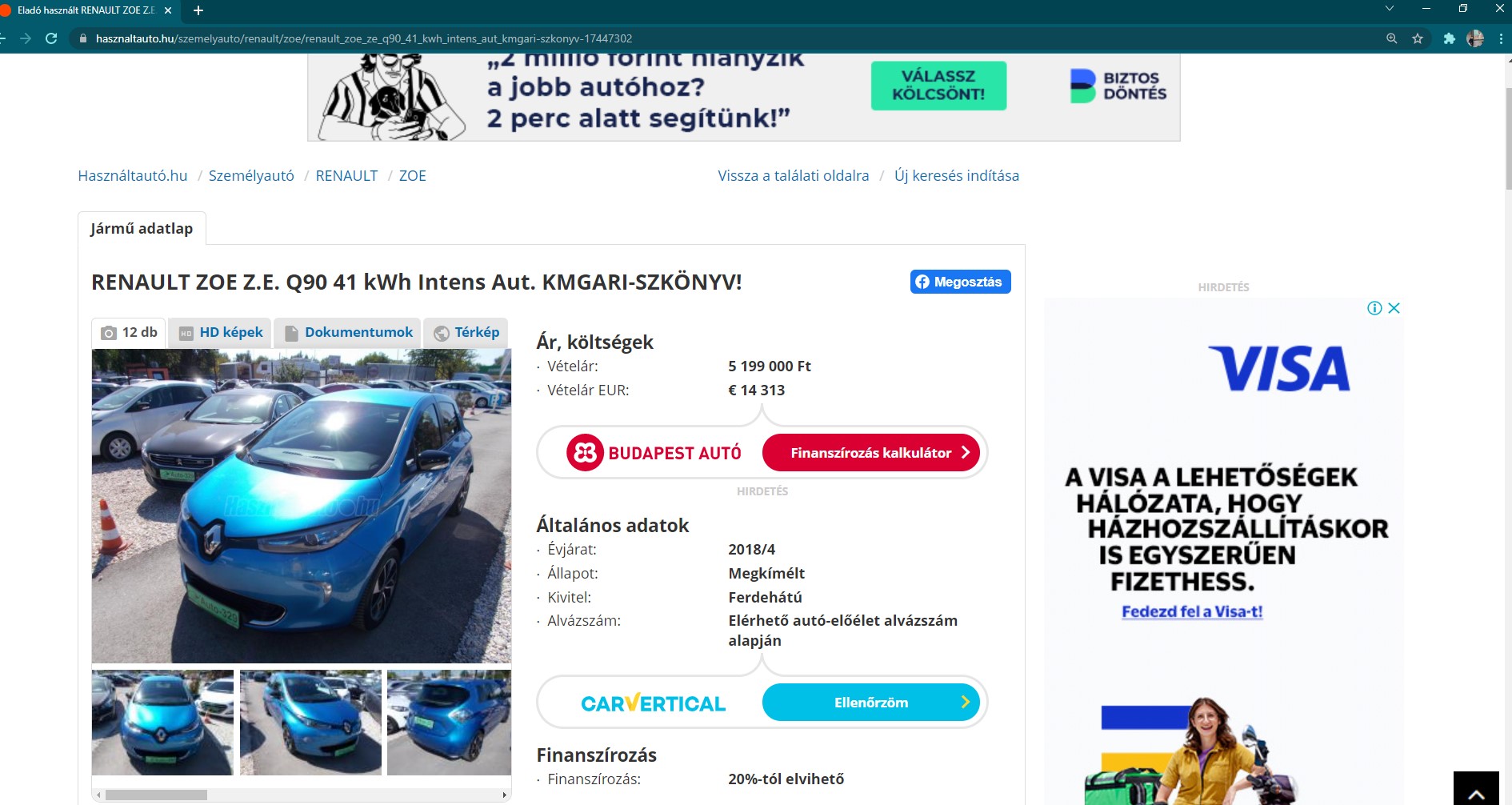
Figure 4.6: A random example of car ad.
You can see that the data is tabulated on the page. This is the best option for us, as you don’t have to search for the item ID on the page one by one (as before with the ad title). You can simply apply the html_table function to a loaded page, which collects all the tables on the it.
car_url <- "https://www.hasznaltauto.hu/szemelyauto/renault/zoe/renault_zoe_ze_q90_41_kwh_intens_aut_kmgari-szkonyv-17447302"
info_tables <- read_html(car_url) %>%
html_table(fill = TRUE)
info_tables
#> [[1]]
#> # A tibble: 31 x 2
#> `Ár, költségek` `Ár, költségek`
#> <chr> <chr>
#> 1 "Vételár:" "5 199 000 Ft"
#> 2 "Vételár EUR:" "€ 14 265"
#> 3 "Finanszírozás kalkulátor ~ "Finanszírozás kalkulátor ~
#> 4 "Általános adatok" "Általános adatok"
#> 5 "Évjárat:" "2018/4"
#> 6 "Állapot:" "Megkímélt"
#> 7 "Kivitel:" "Ferdehátú"
#> 8 "Alvázszám:" "Elérhető autó-előélet alvázszám alap~
#> 9 "Ellenőrzöm" "Ellenőrzöm"
#> 10 "Finanszírozás" "Finanszírozás"
#> # ... with 21 more rowsWhat is the type of info_tables? Since it collects all the tables it can find from the page, it is a list of data frames.
I will reveal that in some cases we will see that there are multiple tables on a page (certain types of info are taken separately) and we want to avoid an irrelevant single column table causing an error (step 1).
Our goal is to be able to gather all the data about the car into a single two-column table. To join all two column tables (step 3), they must also have the same name (step 2).
info_tables %>%
keep(~ ncol(.) == 2) %>% # keep tables that have 2 columns
map(set_names, "x", "y") %>% # set the names to x and y for each table
bind_rows() # join the tables to one sinle table
#> # A tibble: 31 x 2
#> x y
#> <chr> <chr>
#> 1 "Vételár:" "5 199 000 Ft"
#> 2 "Vételár EUR:" "€ 14 265"
#> 3 "Finanszírozás kalkulátor ~ "Finanszírozás kalkulátor ~
#> 4 "Általános adatok" "Általános adatok"
#> 5 "Évjárat:" "2018/4"
#> 6 "Állapot:" "Megkímélt"
#> 7 "Kivitel:" "Ferdehátú"
#> 8 "Alvázszám:" "Elérhető autó-előélet alvázszám alap~
#> 9 "Ellenőrzöm" "Ellenőrzöm"
#> 10 "Finanszírozás" "Finanszírozás"
#> # ... with 21 more rowsWe see that this works, the output now is one single table. Lets use this method on all the links. To do this, we need to write a function.
get_data <- function(url_to_car) {
url_to_car %>%
read_html() %>%
html_table(fill = TRUE) %>%
keep(~ ncol(.) == 2) %>%
map(~ set_names(., "x", "y")) %>%
bind_rows()
}
get_data(car_url)
#> # A tibble: 31 x 2
#> x y
#> <chr> <chr>
#> 1 "Vételár:" "5 199 000 Ft"
#> 2 "Vételár EUR:" "€ 14 265"
#> 3 "Finanszírozás kalkulátor ~ "Finanszírozás kalkulátor ~
#> 4 "Általános adatok" "Általános adatok"
#> 5 "Évjárat:" "2018/4"
#> 6 "Állapot:" "Megkímélt"
#> 7 "Kivitel:" "Ferdehátú"
#> 8 "Alvázszám:" "Elérhető autó-előélet alvázszám alap~
#> 9 "Ellenőrzöm" "Ellenőrzöm"
#> 10 "Finanszírozás" "Finanszírozás"
#> # ... with 21 more rowsThe resulting table can all be collected in a single column of our table. Each cell will be a table that we all collected from a given link.
This can also take a serious amount of time if we want to retrieve data from hundreds of cars at once. You should always use only a few. Use the sample_n function to randomly select a few lines to test if everything works as expected.
cars_add_df %>%
sample_n(size = 3) %>% # remove this line at the end if everything is fine
mutate(
data = map(url_to_cars, get_data)
)
#> # A tibble: 3 x 3
#> url_to_cars ad_title data
#> <chr> <chr> <list>
#> 1 https://www.hasznaltauto.hu/szemel~ OPEL MOKKA 1.2 T Edition CÉGEKN~ <tibble ~
#> 2 https://www.hasznaltauto.hu/szemel~ MERCEDES-BENZ E 200 d 9G-TRONIC~ <tibble ~
#> 3 https://www.hasznaltauto.hu/szemel~ MERCEDES-BENZ GLC-OSZTÁLY GLC 4~ <tibble ~Currently, our small table is also nested in a cell. Expand it!
cars_add_df %>%
sample_n(size = 3) %>% # remove this line at the end if everything is fine
mutate(
data = map(url_to_cars, get_data)
) %>%
unnest()
#> # A tibble: 107 x 4
#> url_to_cars ad_title x y
#> <chr> <chr> <chr> <chr>
#> 1 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Vételár: 14 290 000 Ft
#> 2 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Vételár~ € 39 209
#> 3 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Általán~ Általános ad~
#> 4 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Évjárat: 2017/6
#> 5 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Állapot: Kitűnő
#> 6 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Kivitel: Sedan
#> 7 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Alvázsz~ Elérhető aut~
#> 8 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Ellenőr~ Ellenőrzöm
#> 9 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Jármű a~ Jármű adatok
#> 10 https://www.hasznaltauto.hu~ MERCEDES-AMG E 43 4Matic~ Kilomét~ 112 651 km
#> # ... with 97 more rowsNow that we have a lot of rows instead of 3, the url in the first row is repeated as many times as the number of rows in the table next to it so far.
Since the x column now has the variable name and the y column has the value of the variable, we need another super useful function we’ve seen before: pivot_wider!
cars_add_df %>%
sample_n(size = 3) %>% # remove this line at the end if everything is fine
mutate(
data = map(url_to_cars, get_data)
) %>%
unnest() %>%
pivot_wider(names_from = "x", values_from = "y")
#> # A tibble: 3 x 42
#> url_to_cars ad_title `Vételár:` `Vételár EUR:` `Általános adat~ `Évjárat:`
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 https://www.~ MERCEDES-~ 14 290 00~ € 39 209 Általános adatok 2017/6
#> 2 https://www.~ BMW 530e ~ 19 700 00~ € 54 053 Általános adatok 2021/2
#> 3 https://www.~ VOLVO XC6~ 20 490 00~ € 56 220 Általános adatok 2020/7
#> # ... with 36 more variables: Állapot: <chr>, Kivitel: <chr>, Alvázszám: <chr>,
#> # Ellenőrzöm <chr>, Jármű adatok <chr>, Kilométeróra állása: <chr>,
#> # Szállítható szem. száma: <chr>, Ajtók száma: <chr>, Szín: <chr>,
#> # Saját tömeg: <chr>, Teljes tömeg: <chr>, Csomagtartó: <chr>,
#> # Klíma fajtája: <chr>, Tető: <chr>, Motor adatok <chr>, Üzemanyag: <chr>,
#> # Hengerűrtartalom: <chr>, Teljesítmény: <chr>, Henger-elrendezés: <chr>,
#> # Hajtás: <chr>, Sebességváltó fajtája: <chr>, Okmányok <chr>, ...The last thing that causes this headache for this task is the special characters used in the Hungarian language. The janitor, on the other hand, handles this smoothly as well.
We can now download all the cars if we wish!
cars_data_df <- cars_add_df %>%
mutate(
data = map(url_to_cars, get_data)
) %>%
unnest() %>%
pivot_wider(names_from = "x", values_from = "y") %>%
janitor::clean_names()
cars_data_df
#> # A tibble: 239 x 63
#> url_to_cars ad_title vetelar vetelar_eur finanszirozas_k~ altalanos_adatok
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 https://www~ SSANGYONG~ 6 999 ~ € 19 204 "Finanszírozás ~ Általános adatok
#> 2 https://www~ CITROEN G~ 7 780 ~ € 21 347 "Finanszírozás ~ Általános adatok
#> 3 https://www~ SUZUKI SW~ <NA> € 13 283 <NA> Általános adatok
#> 4 https://www~ PEUGEOT 2~ <NA> € 15 873 "Finanszírozás ~ Általános adatok
#> 5 https://www~ OPEL COMB~ <NA> € 11 483 <NA> Általános adatok
#> 6 https://www~ OPEL INSI~ <NA> € 18 271 <NA> Általános adatok
#> 7 https://www~ OPEL ZAFI~ <NA> € 22 879 <NA> Általános adatok
#> 8 https://www~ SUZUKI VI~ <NA> € 16 271 <NA> Általános adatok
#> 9 https://www~ SUZUKI IG~ <NA> € 13 307 <NA> Általános adatok
#> 10 https://www~ CITROEN C~ 8 600 ~ € 23 597 "Finanszírozás ~ Általános adatok
#> # ... with 229 more rows, and 57 more variables: atveheto <chr>, evjarat <chr>,
#> # allapot <chr>, kivitel <chr>, finanszirozas <chr>, finanszirozas_2 <chr>,
#> # finanszirozas_tipusa_casco_val <chr>,
#> # finanszirozas_tipusa_casco_nelkul <chr>, kezdoreszlet_casco_nelkul <chr>,
#> # havi_reszlet_casco_nelkul <chr>, futamido_casco_nelkul <chr>,
#> # garancia <chr>, garancia_2 <chr>, atrozsdasodasi_garancia <chr>,
#> # szavatossagi_garancia <chr>, jarmu_adatok <chr>, ...